Introduction
Background
What is a meta-analysis?
A meta-analysis is a quantitative summary of studies on the same topic.
Why do we want to perform a meta-analysis?
- Finding generalities
- Increasing power and precision
- Exploring differences between studies
- Settling controversies from conflicting studies (testing hypotheses)
- Generating new hypotheses
The process of meta-analysis
How many steps involved in meta-analysis?
One answer is 5 steps
- Formulating questions & hypothesis or finding a topic
- Literature search & paper collection
- Data extraction & coding
- Meta-analysis & publication bias tests
- Reporting & publication
We only consider the step iv in this tutorial. You will need to learn the other steps elsewhere. To get you started, we recently wrote an overview paper which divides the process of meta-analysis into 10 questions (Nakagawa et al. 2017). The 10 questions will guide you through judging the quality of a meta-analysis.
- Is the search systematic and transparently documented?
- What question and what effect size?
- Is non-independence taken into account?
- Which meta-analytic model?
- Is the level of consistency among studies reported?
- Are the causes of variation among studies investigated?
- Are effects interpreted in terms of biological importance?
- Has publication bias been considered?
- Are results really robust and unbiased?
- Is the current state (and lack) of knowledge summarized?
Metafor for meta-analysis
I think the R package metafor (Viechtbauer 2010) is the most comprehensive meta-analytic software and the author Wolfgang Viechtbauer, who, I have to say, has the coolest name among my friends, is still actively developing it.
First, install and load the metafor package.
library(metafor)Have a look at the data set named dat.curtis1998 included in the package. If you have to see the other data sets included in this package, try help(package="metafor").
dat <- metafor::dat.curtis1998
str(dat)## 'data.frame': 102 obs. of 20 variables:
## $ id : int 21 22 27 32 35 38 44 63 86 87 ...
## $ paper : int 44 44 121 121 121 121 159 183 209 209 ...
## $ genus : chr "ALNUS" "ALNUS" "ACER" "QUERCUS" ...
## $ species : chr "RUBRA" "RUBRA" "RUBRUM" "PRINUS" ...
## $ fungrp : chr "N2FIX" "N2FIX" "ANGIO" "ANGIO" ...
## $ co2.ambi: num 350 350 350 350 350 350 350 395 350 350 ...
## $ co2.elev: num 650 650 700 700 700 700 700 795 700 700 ...
## $ units : chr "ul/l" "ul/l" "ppm" "ppm" ...
## $ time : int 47 47 59 70 64 50 730 365 365 365 ...
## $ pot : chr "0.5" "0.5" "2.6" "2.6" ...
## $ method : chr "GC" "GC" "GH" "GH" ...
## $ stock : chr "SEED" "SEED" "SEED" "SEED" ...
## $ xtrt : chr "FERT" "FERT" "NONE" "NONE" ...
## $ level : chr "HIGH" "CONTROL" "." "." ...
## $ m1i : num 6.82 2.6 2.99 5.91 4.61 ...
## $ sd1i : num 1.77 0.667 0.856 1.742 1.407 ...
## $ n1i : int 3 5 5 5 4 5 3 3 20 16 ...
## $ m2i : num 3.94 2.25 1.93 6.62 4.1 ...
## $ sd2i : num 1.116 0.328 0.552 1.631 1.257 ...
## $ n2i : int 5 5 5 5 4 3 3 3 20 16 ...This data set is from the paper by Curtis and Wang (1998). They looked at the effect of increased CO\(_2\) on plant traits (mainly changes in biomass). So we have information on control group (1) and experimental group (2) (m = mean, sd = standard deviation) along with species information and experimental details. In meta-analysis, these variables are often referred to as ‘moderators’ (we will get to this a bit later).

Calculating ‘standardized’ effect sizes
To compare the effect of increased CO\(_2\) across multiple studies, we first need to calculate an effect size for each study - a metric that quantifies the difference between our control and experimental groups.
There are several ‘standardized’ effect sizes, which are unit-less. When we have two groups to compare, we use two types of effect size statistics. The first one is standardized mean difference (SMD or also known as Cohen’s \(d\) or Hedge’s \(d\) or \(g\); some subtle differences between them, but we do not worry about them for now):
\[\begin{equation} \mathrm{SMD}=\frac{\bar{x}_{E}-\bar{x}_{C}}{\sqrt{\frac{(n_{C}-1)sd^2_{C}+(n_{E}-1)sd^2_{E}}{n_{C}+n_{E}-2}}} \end{equation}\] where \(\bar{x}_{C}\) and \(\bar{x}_{E}\) are the means of the control and experimental group, respectively, \(sd\) is sample standard deviation (\(sd^2\) is sample variance) and \(n\) is sample size.
And its sample error variance is:
\[\begin{equation} se^2_{\mathrm{SMD}}= \frac{n_{C}+n_{E}}{n_{C}n_{E}}+\frac{\mathrm{SMD}^2}{2(n_{C}+n_{E})} \end{equation}\]
The square root of this is referred to as ‘standard error’ (or the standard deviation of the estimate – confused?). The inverse of this (\(1/se^2\)) is used as ‘weight’, but things are bit more complicated than this as we will find out below.
Another common index is called ‘response ratio’, which is usually presented in its natural logarithm form (lnRR):
\[\begin{equation} \mathrm{lnRR}=\ln\left({\frac{\bar{x}_{E}}{\bar{x}_{C}}}\right) \end{equation}\]
And its sampling error variance is:
\[\begin{equation} se^2_\mathrm{lnRR}=\frac{sd^2_{C}}{n_{C}\bar{x}^2_{C}}+\frac{sd^2_{E}}{n_{E}\bar{x}^2_{E}} \end{equation}\]
Let’s get these using the function escalc in metafor. To obtain the standardised mean difference, we use:
# SMD
SMD <- escalc(measure = "SMD", n1i = dat$n1i, n2i = dat$n2i, m1i = dat$m1i, m2i = dat$m2i,
sd1i = dat$sd1i, sd2i = dat$sd2i)where n1i and n2i are the sample sizes, m1i and m2i are the means, and sd1i and sd2i the standard deviations from each study.
The oject created now has an effect size (yi) and its variance (vi) for each study
## yi vi
## 1 1.8222 0.7408
## 2 0.5922 0.4175
## 3 1.3286 0.4883
## 4 -0.3798 0.4072
## 5 0.3321 0.5069
## 6 2.5137 0.9282To obtain the response ratio (log transformed ratio of means), we would use:
lnRR <- escalc(measure = "ROM", n1i = dat$n1i, n2i = dat$n2i, m1i = dat$m1i, m2 = dat$m2i,
sd1i = dat$sd1i, sd2i = dat$sd2i)The original paper used lnRR so we will use it, but you may want to repeat analysis below using SMD to see whether results are consistent.
Add the effect sizes to the original data set with cbind or bind_cols from the package dplyr
library(dplyr)
dat <- bind_cols(dat, lnRR)You should see yi (effec size) and vi (sampling variance) are added.
## 'data.frame': 102 obs. of 22 variables:
## $ id : int 21 22 27 32 35 38 44 63 86 87 ...
## $ paper : int 44 44 121 121 121 121 159 183 209 209 ...
## $ genus : chr "ALNUS" "ALNUS" "ACER" "QUERCUS" ...
## $ species : chr "RUBRA" "RUBRA" "RUBRUM" "PRINUS" ...
## $ fungrp : chr "N2FIX" "N2FIX" "ANGIO" "ANGIO" ...
## $ co2.ambi: num 350 350 350 350 350 350 350 395 350 350 ...
## $ co2.elev: num 650 650 700 700 700 700 700 795 700 700 ...
## $ units : chr "ul/l" "ul/l" "ppm" "ppm" ...
## $ time : int 47 47 59 70 64 50 730 365 365 365 ...
## $ pot : chr "0.5" "0.5" "2.6" "2.6" ...
## $ method : chr "GC" "GC" "GH" "GH" ...
## $ stock : chr "SEED" "SEED" "SEED" "SEED" ...
## $ xtrt : chr "FERT" "FERT" "NONE" "NONE" ...
## $ level : chr "HIGH" "CONTROL" "." "." ...
## $ m1i : num 6.82 2.6 2.99 5.91 4.61 ...
## $ sd1i : num 1.77 0.667 0.856 1.742 1.407 ...
## $ n1i : int 3 5 5 5 4 5 3 3 20 16 ...
## $ m2i : num 3.94 2.25 1.93 6.62 4.1 ...
## $ sd2i : num 1.116 0.328 0.552 1.631 1.257 ...
## $ n2i : int 5 5 5 5 4 3 3 3 20 16 ...
## $ yi : num 0.547 0.143 0.438 -0.113 0.117 ...
## ..- attr(*, "ni")= int [1:102] 8 10 10 10 8 8 6 6 40 32 ...
## ..- attr(*, "measure")= chr "ROM"
## $ vi : num 0.0385 0.0175 0.0328 0.0295 0.0468 ...Visualising effect size. We can visualize point estimates (effect size) and their 95% confidence intervals, CIs (based on sampling error variance) by using the forest function, which draws a forest plot for us.
forest(dat$yi, dat$vi)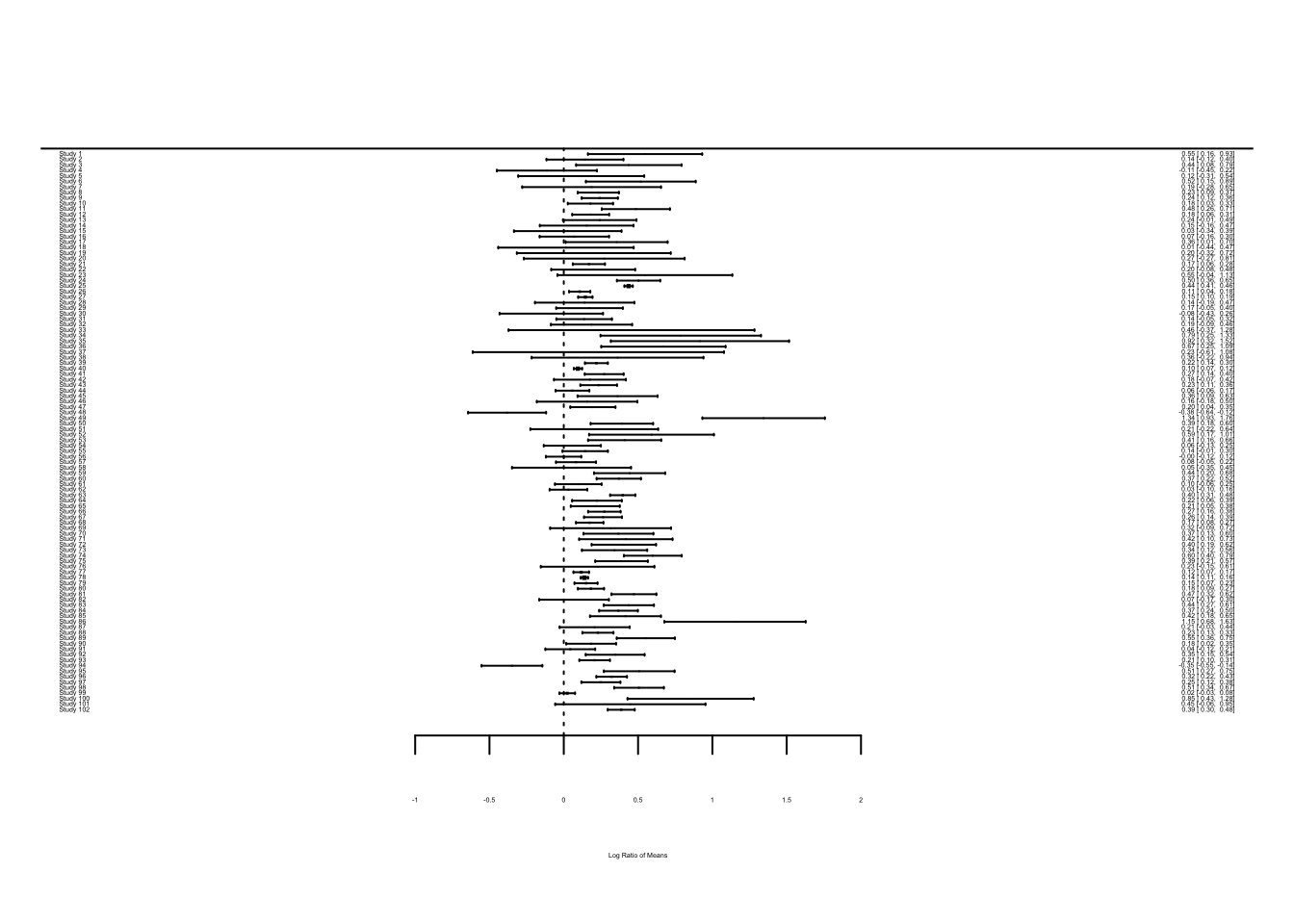
The problem you see is that when there are many studies, a forest plot does not really work (unless you have very large screen!). Let’s look at just the first 12 studies.
forest(dat$yi[1:12], dat$vi[1:12])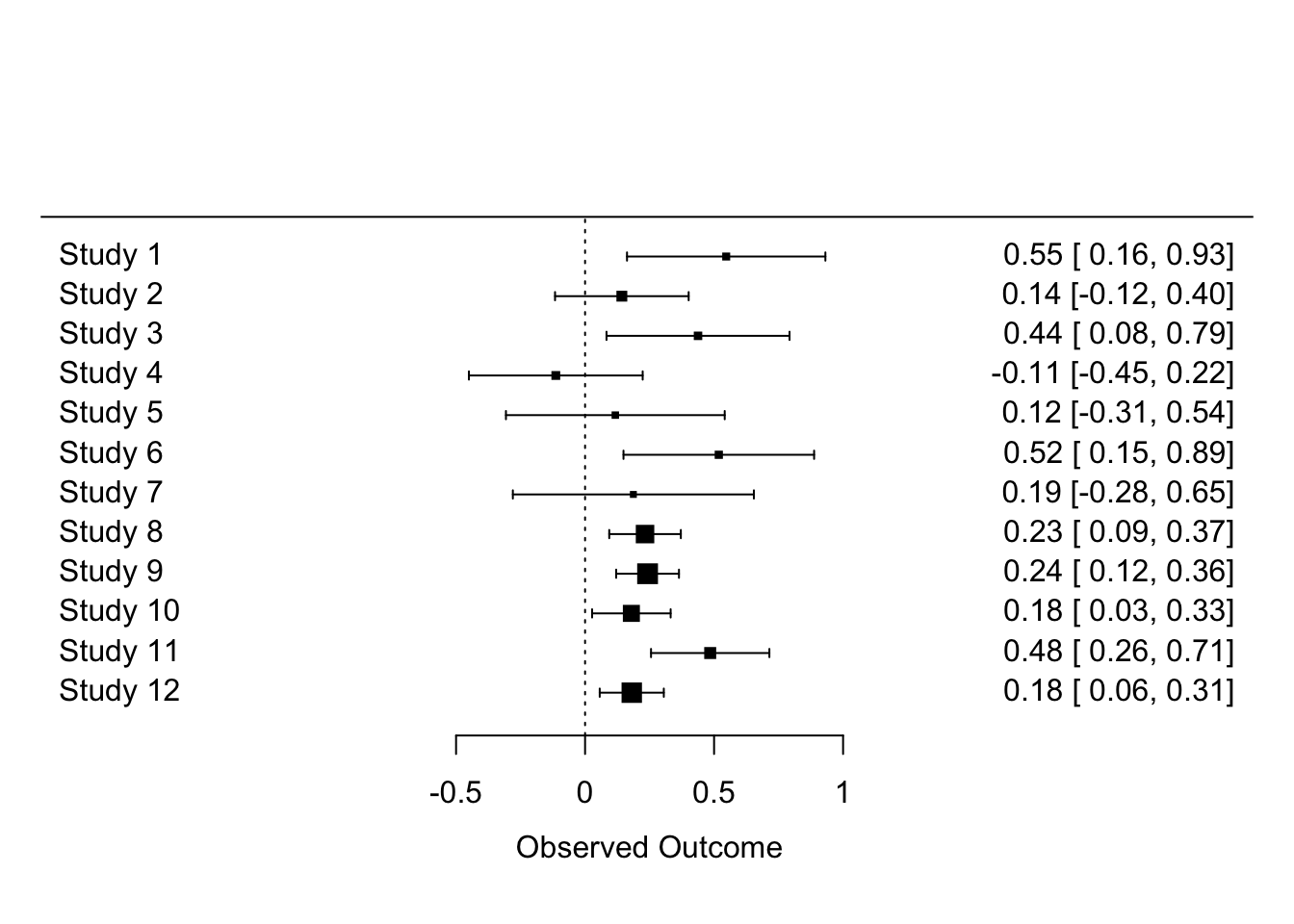
We can calculate many different kinds of effect sizes with escalc; other common effect size statistics include \(Zr\) (Fisher’s z-transformed correlation). By the way, along with my colleagues, I have proposed a new standardized effect size called lnCVR (the log of coefficient of variation ratio – mouthful!), which compares the variability of two groups rather than means. See whether you can calculate it with these data. Actually, the development version of metafor, let you do this with escalc– github page. lnCVR is called “CVR” in escalc. Actually, if you re-analysis this data with lnCVR, you may be able to publish a paper! Nobody has done it yet. Do it tonight!
Once you have calculated effect sizes, move on to the next page: Meta-analysis 2: fixed-effect and random-effect models
Further help (references)
Go to the metafor package’s website. There you find many worked examples.
Curtis, P. S., and X. Z. Wang. 1998. A meta-analysis of elevated CO2 effects on woody plant mass, form, and physiology. Oecologia 113:299-313.
Nakagawa, S., R. Poulin, K. Mengersen, K. Reinhold, L. Engqvist, M. Lagisz, and A. M. Senior. 2015. Meta-analysis of variation: ecological and evolutionary applications and beyond. Methods in Ecology and Evolution 6:143-152.
Viechtbauer, W. 2010. Conducting meta-analyses in R with the metafor package. Journal of Statistical Software 36:1-48.
Authors: Shinichi Nakagawa and Malgorzata (Losia) Lagisz
Year: 2016
Last updated: Feb 2022